



-
近年来,空气污染已经成为了公众所热议的话题,尤其是对于发达城市而言,其影响的人群更多更广。中国空气污染状况呈现出冬半年较严重,夏半年较轻,北方地区较严重,南方地区较轻的分布特征[1]。为了遏制空气污染的进一步恶化,相关部门采取了一系列高效的空气污染防治措施并取得了不错的效果[2],即便如此,仍然不能放缓空气污染防治的脚步,气象部门应不断规范污染预报预警信息的发布,加强气象灾害的防御工作,以便带来不必要的损失。
空气污染带来的危害不仅局限于人体健康方面,其对气候、植物以及生态系统也会产生影响[3-7]。大气污染给人体健康带来的危害是多方面的,主要会造成生理机能障碍和呼吸系统疾病,人体眼睛与鼻子等器官中的粘膜组织受到污染气体的刺激也会引发患病。大气污染物,尤其是二氧化硫、氟化物等对植物的危害也是十分严重的,当污染物浓度很高时,会对植物产生急性危害,使植物叶表面产生伤斑,或者直接使叶片枯萎而脱落;当污染物浓度不高时,会对植物产生慢性危害,尽管表面上危害症状并不明显,但实际上植物的生理机能已受到了侵袭,进而使得产量下降,品质变差。除此之外,大气污染还能对气候产生影响,可以减少到达地面的太阳辐射量,二氧化硫经过氧化会形成硫酸,伴随自然降雨落到地面,破坏建筑物和农作物。
由于空气污染会给居民的生产生活带来不便,因此对于空气质量的准确预报就非常重要。目前国内的学者们在空气污染物浓度预测方面做了诸多尝试,其主要方法有数值预报和统计预报。相比于数值预报,统计预报无需考虑复杂多样的化学物理过程,模型的构建过程比较简单,使用起来也更加方便,尤其是近年来一些机器学习算法在环境和气象预测领域表现优异[8-13],使得统计预报方法的应用越来越广泛。李龙等[14]利用最小二乘支持向量机对PM2.5浓度做了预测,研究发现引入综合气象指数可以使得预测结果的误差降低约30%,此外还发现了PM2.5浓度与住院率、医院门诊量高度相关;刘杰等[15]构建了包括机器学习算法在内的4种模型对PM2.5质量浓度进行了预测,通过对比研究,发现支持向量机可以更好地捕捉到PM2.5质量浓度与预报因子之间的非线性关系,整体的预测准确度更高,可作为首选方法;李勇等[16]将小波分析与BP神经网络相结合对PM10浓度进行了预测,发现结合后的模型比传统的BP模型预测精度更高;梁泽等[17]利用经遗传算法优化的径向基神经网络模型预测了北京市24 小时的平均PM2.5浓度值,结果发现该模型预测性能良好且无需输入地理位置信息与气象等数据,依赖变量少且预测准确率高(R2高达75%),能够对多种时空情境下的城市空气污染物浓度进行预测;为了提高多变天气情况下PM2.5浓度的预测准确率,李芬等[18]对天气类型进行聚类与识别,基于LSTM算法构建了不同天气类型下的PM2.5浓度预测模型,研究发现该方法比传统BP神经网络与支持向量机方法效果更好。本文利用空气质量监测数据(包括SO2、NO2、O3、CO、PM10和PM2.5)与气象数据,基于RF-Kmeans-LIBSVM算法建立PM2.5与PM10日均浓度的预报模型,为相关部门制定决策提供理论依据。
-
空气污染物浓度监测数据来源于环境监测站,气象数据来自天气后报网站(
http://www.tianqihoubao.com/ ),选取乌鲁木齐市的逐日数据,时间段为北京时间2015年1月1日~2020年12月31日,空气污染物浓度监测数据包括的要素为:SO2、NO2、O3、CO、PM10和PM2.5这6种污染物的日均浓度值;气象数据包括的要素为:风向和风速、天气状况、最高和最低气温。首先对数据进行质量控制,将序列中乱码和缺失的数据进行识别与剔除,采用相邻非缺失值线性插值的方法进行订正。为了消除不同量纲单位之间的差异,在建立模型之前需要使用公式(1)将所选数据归一化到指定区间(0,1)内。式中,Xn代表经归一化处理之后的数据,X代表经归一化处理之前的数据,Xmax代表样本数据中的最大值,Xmin代表样本数据中的最小值。
-
随机森林算法(RF)[19-22]是由LEO Breiman教授提出的,该算法能够对特征变量的重要性进行评估,在非线性问题中表现优异,付旭东[23]使用RF重要性评估的方法结合机器学习预测模型有效提高了风场预报的准确率。使用RF算法筛选出重要变量的思想是看每个特征对随机森林中每棵决策树的贡献程度,然后取该特征贡献的平均值,最后依据贡献值大小对每个特征进行排序。通常情况下,可以通过基尼系数对各个因子的贡献大小进行衡量。
-
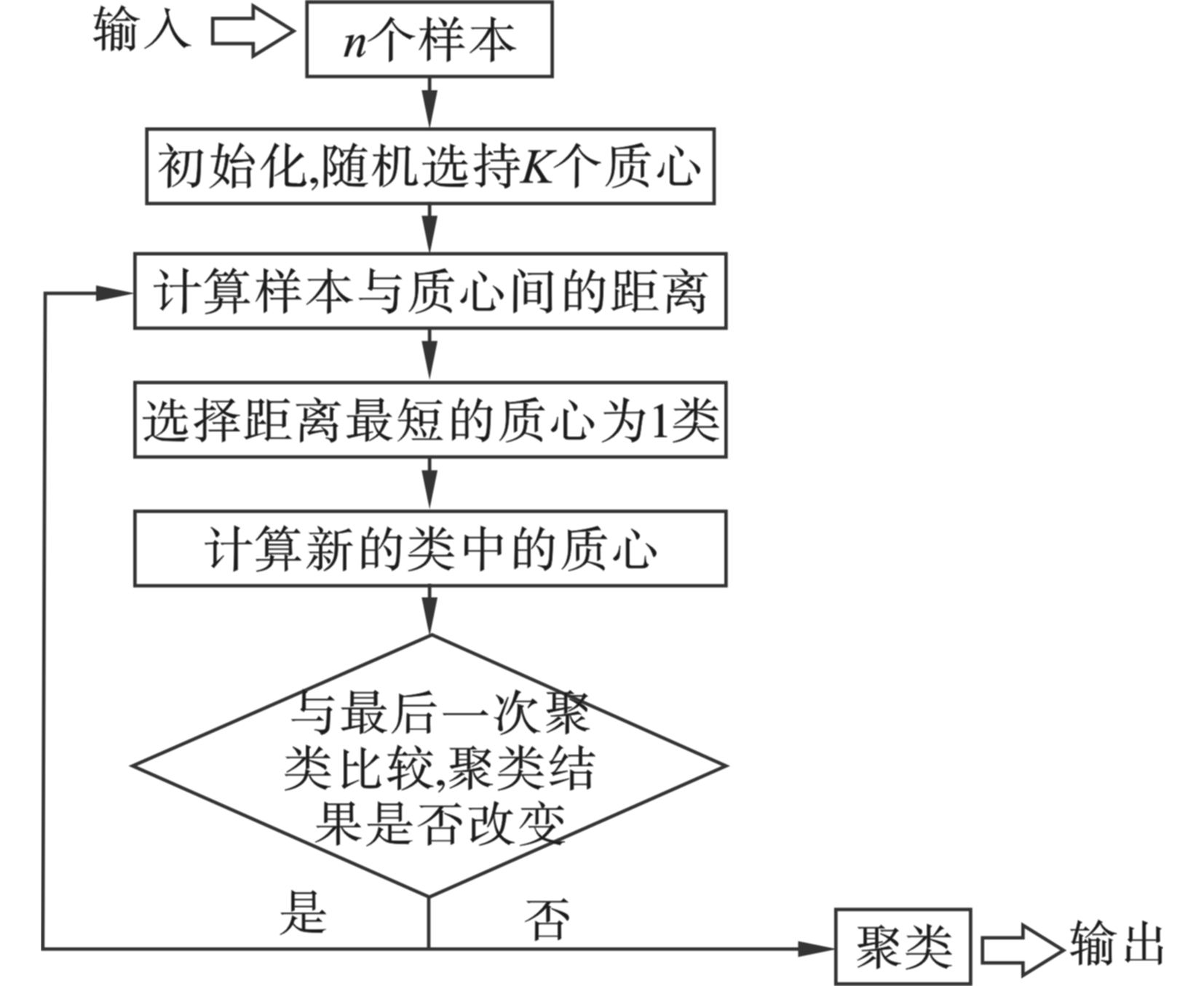
K-Means算法[24]作为应用最为广泛的聚类分析算法之一,是一种非常典型的基于距离的硬聚类算法,认为对象之间的距离越小,相似性就越大。K-Means聚类是基于样本集合划分的聚类算法,它将样本集合划分为K个子集,构成K个类,将n个样本分到K个类中,每个样本到其所属类的中心距离最小,每个样本仅属于一个类。K-Means聚类算法的实现过程,见图1。
-
LIBSVM是由林智仁副教授设计发明的,如今已经被广泛应用于回归拟合问题[25-26]。传统支持向量机预测模型有一个明显的缺点,就是只能依靠经验和对比实验来进行选取核函数以及其他参数,而LIBSVM的出现则克服了这一缺陷。相对于传统支持向量机(SVM)模型,LIBSVM的很多参数都是默认的,涉及到的参数调节更少,合理利用这些设置好的默认参数可用来解决许多问题,LIBSVM还在传统SVM的基础上提供了一种用于交互检验的新功能。
-
选用平均绝对误差(MAE)、均方根误差(RMSE)和预报准确率(P)3个误差评价指标对PM2.5和PM10浓度的预测结果进行检验,每种误差评价指标的计算过程,见式(2~4):
式中, Q和O分别表示颗粒物浓度的预测值和实际监测值,
$\overline O $ 表示实际监测值的平均值,n表示颗粒物浓度数据的试报个数。 -
本文在构建PM2.5和PM10浓度预报模型时,除了考虑前日的6种污染物浓度值和AQI指数对次日PM2.5和PM10浓度的影响外,还考虑了预测日的最高气温、最低气温、风速、风向和天气状况等。为了减小浓度的突然波动对预测结果的影响,这里采用滑动平均法对污染物浓度进行3 d滑动平均处理。将预测日的天气状况进行分类,分为晴、阴、多云、雾、雨、雪和雨夹雪等7种天气类型,并将以上7种天气类型分别用数字1~7表示;风向用角度值表示。颗粒物浓度预报中预报因子的变量符号及其物理意义,见表1。其中,X表示输入变量,Y表示输出变量。
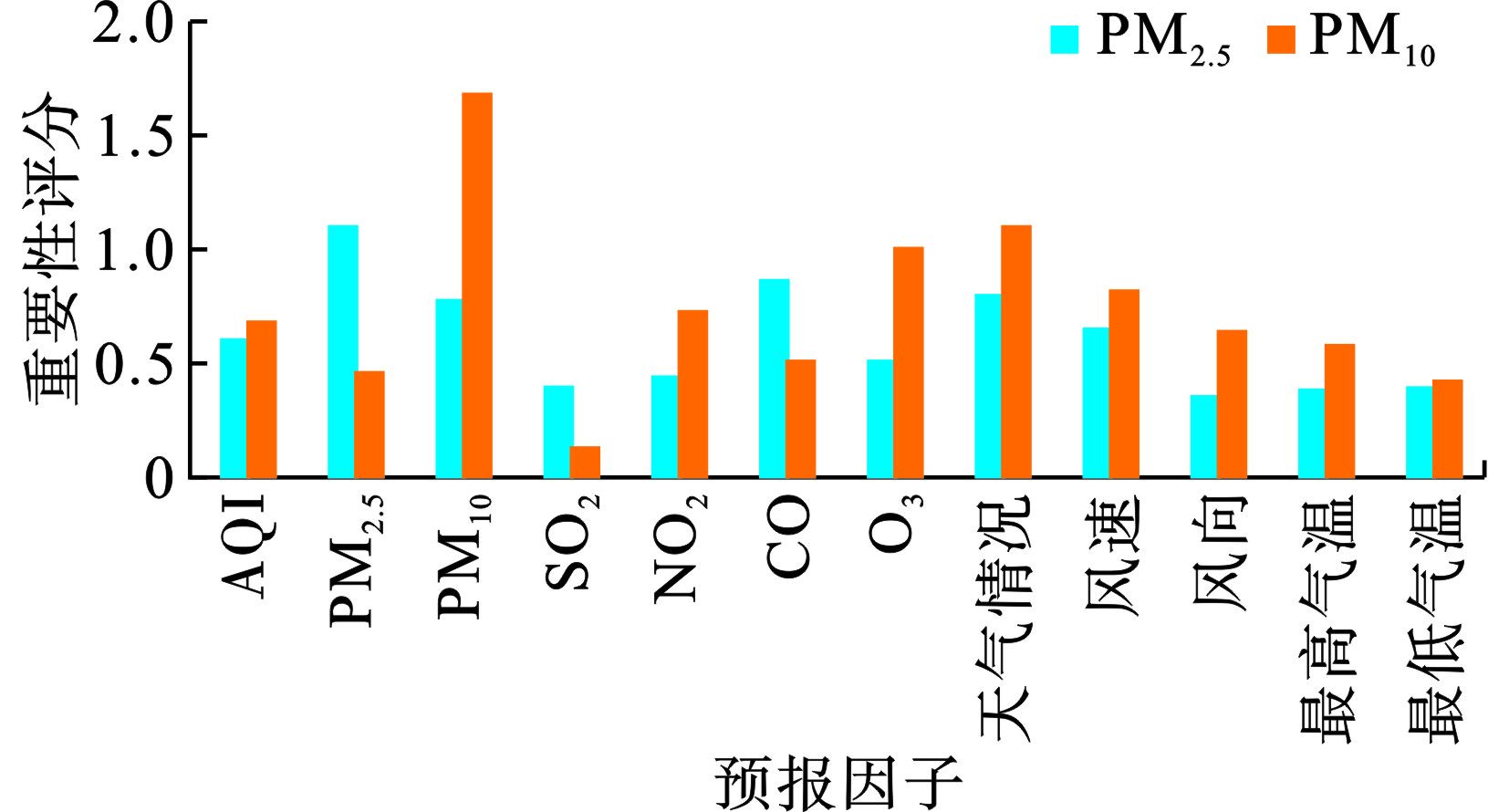
颗粒物浓度预测中影响PM2.5和PM10浓度的因子重要性评分,见图2。
对于PM2.5而言,排名在前3位的预报因子依次为前日的PM2.5浓度、前日的CO浓度和预测日的天气状况;对于PM10而言,排名在前3位的预报因子依次为前日的PM10浓度、预测日的天气状况和前日的O3浓度。总的来说,当以某种颗粒物浓度作为输出变量时,前日的该颗粒物浓度对预报结果的贡献最大,预测日的天气状况也是一个不容忽视的预报因子。
-
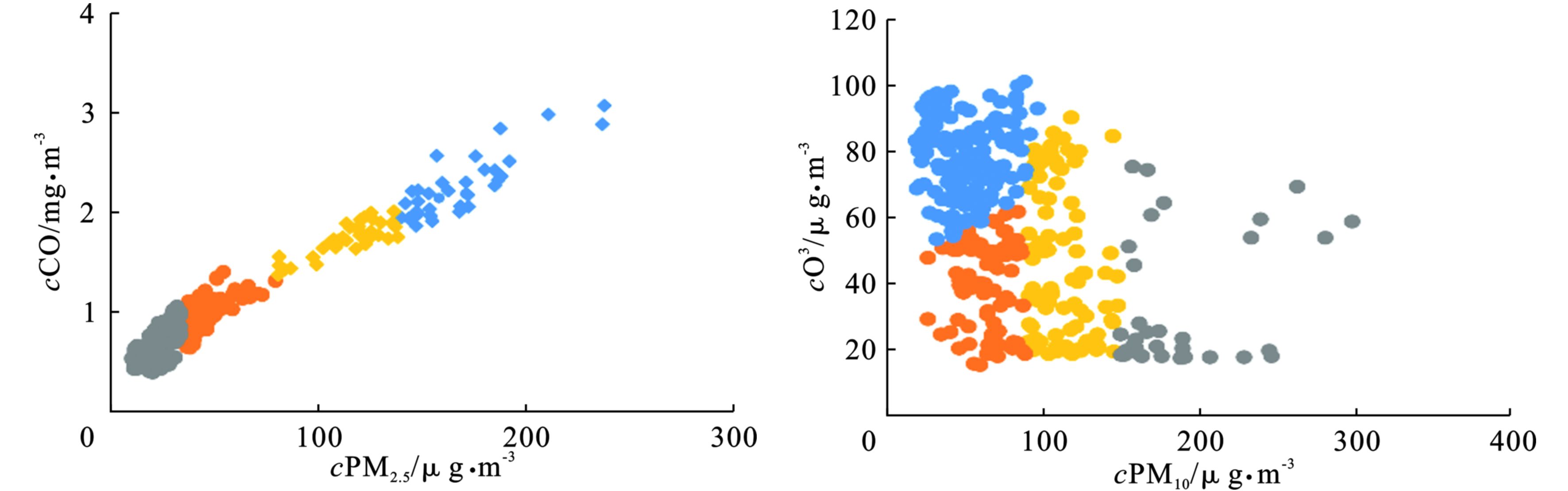
对于PM2.5而言,选择重要性评分最高的2个因子进行聚类运算,它们分别为前日的PM2.5浓度和前日的CO浓度;对于PM10而言,重要性评分最高的因子为前日的PM10浓度,预测日的天气状况与前日的O3浓度紧随其后且两者的评分大小相差不大,考虑到天气状况的数据是通过定性分析转化而来的,数据精度不高,因此选择前日的PM10浓度和前日的O3浓度进行聚类运算。经试验发现,当K
值﹤2或﹥7时,PM2.5模型的训练误差会明显增大,当K值﹤3或﹥8时,PM10模型的训练误差会明显增大,因此,从2~8依次设置K值,利用SPSS软件进行聚类分析,可得到不同K值下的聚类数据与质心,经过多次统计尝试发现当PM2.5和PM10都被分为4个类别时预测效果最好。K=4时颗粒物的数据样本聚类结果,将PM2.5和PM10各自分为4个类别,针对每个类别的数据分别建立模型,见图3。 经聚类分析后基本能够将不同浓度范围的颗粒物浓度值分开,分为4类,然后针对每一类分别构建预报模型,减少数据的样本差异给预报结果带来的干扰,降低模型的过拟合程度,提高预测精度,见表2。
-
利用LIBSVM的回归原理构建大气颗粒物浓度预报模型。将数据集划分为训练数据和测试数据,其中训练数据和测试数据又各自包含输入数据与输出数据。选取2015年1月1日~2019年12月31的数据作为训练数据,2020年1月1日~2020年12月31日的数据作为测试数据,以此来构建基于LIBSVM的颗粒物浓度预报模型。
(1)调入数据,对数据进行归一化处理。
(2)利用RF-Kmeans算法对颗粒物数据进行聚类运算,将PM2.5和PM10分别分成4种不同类别。
(3)采用LIBSVM算法对各个类别的模型分别进行训练。
(4)将测试数据中的输入数据输入到已经训练好的预报模型中,输出经模型预报的颗粒物浓度数据。
(5)反归一化,得到空气颗粒物浓度预报值的最终结果。
(6)对模型输出的空气颗粒物浓度预报结果进行误差分析,评价模型的泛化能力。
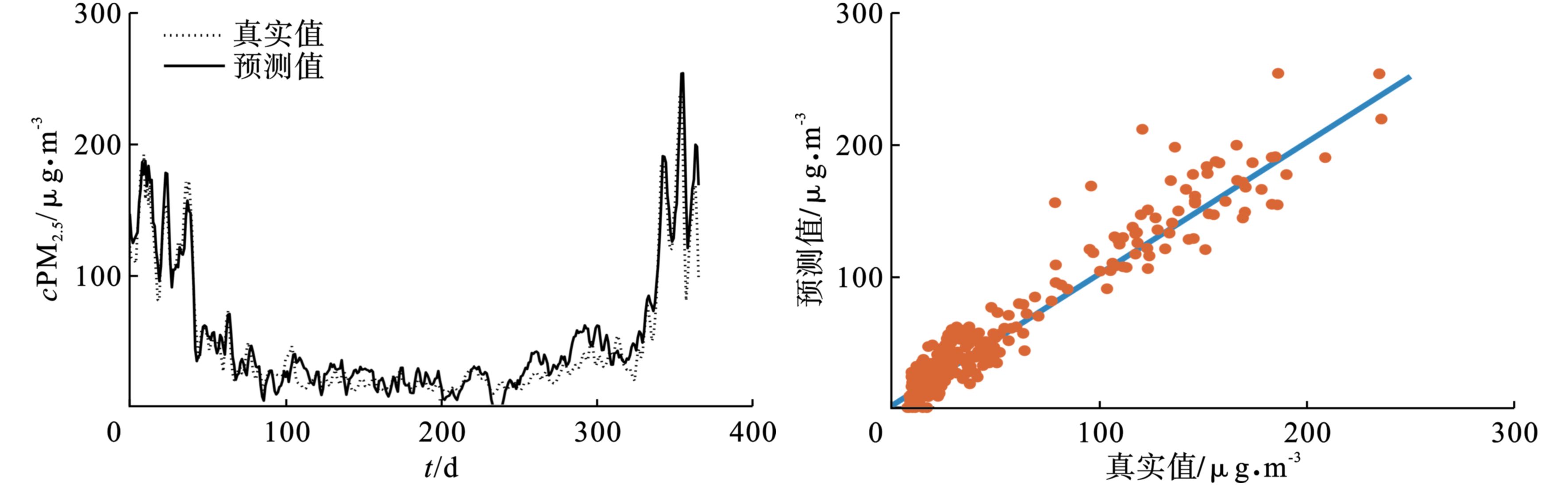
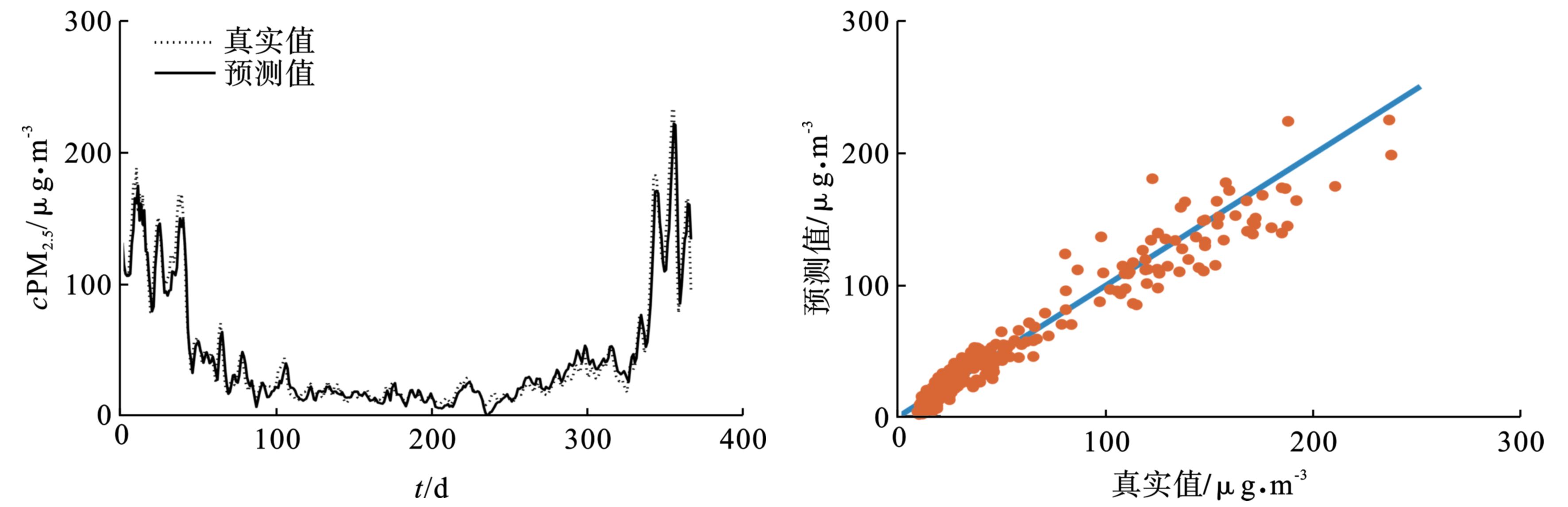
根据以上建模步骤,给出了不同颗粒物浓度序列的RF-Kmeans-LIBSVM预测结果,见图4和5。
总体上,颗粒物的预测值能够较好地反映出真实值的变化趋势。从预测值与真实值之间的相关程度来看,无论是PM2.5还是PM10,相关系数都在0.54以上:对于PM2.5来说,第一类为0.83,第二类为0.69,第三类为0.54,第四类为0.73;对于PM10来说,第一类为0.81,第二类为0.67,第三类为0.55,第四类为0.66;这说明预测值与真实值之间有较高的正相关关系。
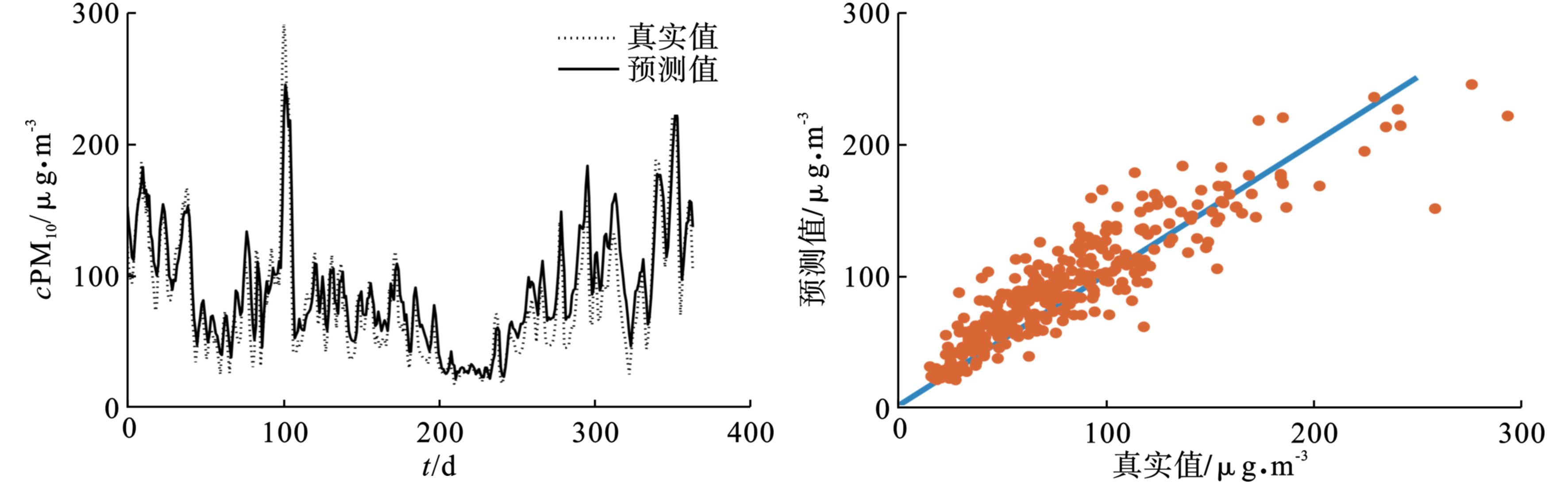
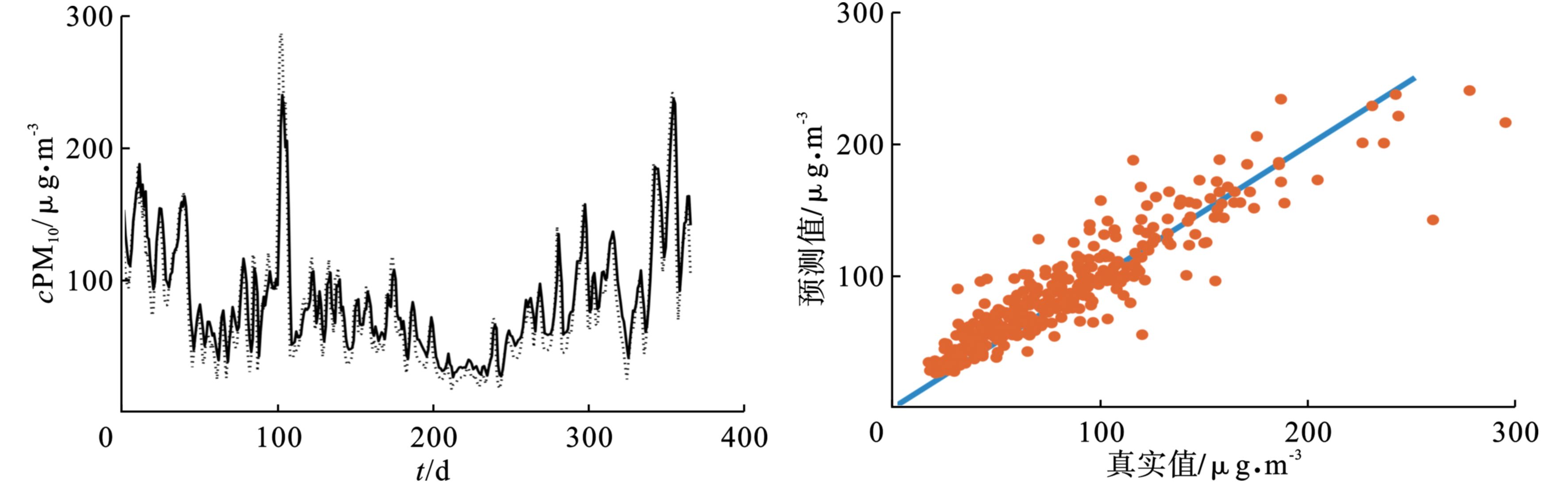
为了验证该模型的泛化能力,本文采用未经聚类分析的传统LIBSVM模型对颗粒物浓度进行预测,为了更加直观地对比模型优化前后的整体预测效果,首先将聚类分析后得到的颗粒物预测数据按照时间的先后顺序进行整合,得到整体的颗粒物浓度序列预测结果,再对实际监测值和预测值之间进行相关性分析。若实际监测值与预测值之间相差较小,则在相关性分析图中呈现为收敛,即相关性较好,反之则呈现为发散,相关性较差。各图中的折线图表示PM2.5和PM10实际即监测值与预测值的对比效果图,散点图表示实际监测值与预测值之间的相关性分析图,预测结果见,图6~9。
图中可以看出,颗粒物的预测值能够较好地反映真实值的大小及变化趋势,预测值与真实值之间的相关程度较高,对PM2.5而言,LIBSVM模型的相关系数为0.961,RF-Kmeans-LIBSVM模型的相关系数为0.975;对PM10而言,LIBSVM模型的相关系数为0.906,RF-Kmeans-LIBSVM模型的相关系数为0.919。
相对于传统的LIBSVM预测方法,经聚类分析优化之后的RF-Kmeans-LIBSVM预测方法的各项误差评价指标得到明显提升,说明RF-Kmeans聚类方法能够为模型提供相似度较高的训练样本,从而提高训练效率,进而使得模型的泛化能力得到显著提高,见表3。
从预测整体效果方面看,本方法通过聚类分析对模型实现了优化,在对PM2.5的预测中,MAE、RMSE分别下降了33.1%和26.5%,准确率提高了7.4%;在对PM10的预测中,MAE、RMSE分别下降了15.7%和12.7%,准确率提高了3.3%,表明了该方法能够大幅度地提高LIBSVM模型对大气颗粒物浓度的预测性能,具有一定的实用价值,可为颗粒物质量浓度的预测业务提供参考。
-
本研究基于乌鲁木齐市2015~2020年的空气污染资料与气象资料,利用RF-Kmeans的聚类方法对空气颗粒物数据进行分型,结合支持向量机回归模型对PM2.5和PM10质量浓度分别进行了预报,主要结论如下。
一是在所选预报因子中,前日的PM2.5浓度对预测日PM2.5浓度预测的贡献最大,其次是前日的CO浓度和预测日的天气状况,前日的PM10浓度对预测日PM10浓度预测的贡献最大,其次是预测日的天气状况和前日的O3浓度。
二是使用RF-Kmeans聚类方法将颗粒物浓度数据分成相似度较高的若干类,针对每一类分别构建预测模型,并用各类颗粒物浓度数据训练各类模型,不仅可以提高模型的训练速度, 还可以提高模型对此类数据的泛化能力,提高模型的预测准确率。
三是相对于传统支持向量机预测模型,该预测方法对PM2.5预测结果的MAE、RMSE分别下降了33.1%和26.5%,对PM10预测结果的MAE、RMSE分别下降了15.7%和12.7%。可将该方法推广至乌鲁木齐市空气质量预报业务中,为空气质量业务化预报提供技术支撑。
基于RF-Kmeans-LIBSVM的乌鲁木齐市颗粒物浓度预测研究
Particle concentration forecast of Urumqi based on RF-Kmeans-LIBSVM
-
摘要: 为了准确预测空气中颗粒物的浓度变化情况,减少空气污染给居民的生产生活带来的危害,该研究提出一种基于RF-Kmeans-LIBSVM的大气颗粒物浓度预测模型。首先采用RF算法对影响PM2.5和PM10浓度的因子进行重要性评估,选择出影响最大的2个因子作为聚类属性,然后采用Kmeans算法对空气污染监测数据进行聚类,把PM2.5和PM10序列划分为相似性较高的若干类,最后运用经聚类分析之后的训练样本建立PM2.5和PM10浓度预测模型。以乌鲁木齐市监测点2015年1月1日~2020年12月31日的PM2.5和PM10浓度日均监测数据为例,使用改进方法和传统方法分别进行预测。结果表明:与传统支持向量机相比,改进后的模型的预测准确率明显提升,对于PM2.5,误差评价指标MAE和RMSE分别下降33.1%和26.5%;对于PM10,误差评价指标MAE和RMSE分别下降15.7%和12.7%。研究说明利用RF-Kmeans聚类分析的方法来提高传统支持向量机在PM2.5和PM10浓度预测中的泛化能力具有可行性。Abstract: In order to accurately predict the concentration of particulate matter in the air and reduce the harm caused by air pollution to the residents, this study proposes an atmospheric particulate matter concentration prediction model based on RF-Kmeans-LIBSVM. First, the RF algorithm is used to evaluate the importance of the factors that affect PM2.5, PM10 concentration. The two serious influential factors in the factor set are selected as clustering attributes, and then the Kmeans algorithm is used to cluster the air pollution monitoring data. PM2.5, PM10 sequences are divided into several categories with the high similarity. Finally, the training samples after cluster analysis are used to establish a PM2.5, PM10 concentration prediction model. Taking the daily average PM2.5, PM10 concentration monitoring data from the monitoring point in Urumqi from January 1, 2015 to December 31, 2020 as an example, the forecast is performed by the improved method and the traditional method. The results show that compared with the traditional support vector machine, the prediction accuracy of the improved model is significantly increased. For PM2.5, the error evaluation indexes MAE and RMSE decrease by 33.1% and 26.5%, respectively. For PM10, the error evaluation indexes MAE and RMSE decrease by 15.7% and 12.7%, respectively. The study shows that it is feasible to use the RF-Kmeans cluster analysis method to improve the generalization ability of traditional support vector machines in PM2.5, PM10 concentration prediction.
-
Key words:
- PM2.5 /
- PM10 /
- cluster analysis /
- support vector machine /
- forecast
-
-
表 1 颗粒物物浓度预测中预报因子的变量符号及其物理意义
变量 变量符号 物理意义 输入变量 X1 前日的PM2.5浓度 X2 前日的PM10浓度 X3 前日的SO2浓度 X4 前日的NO2浓度 X5 前日的O3浓度 X6 前日的CO浓度 X7 前日的AQI指数 X8 预测日的最高气温 X9 预测日的最低气温 X10 预测日的天气状况 X11 预测日的风速 X12 预测日的风向 输出变量 Y1 预测日PM2.5浓度 Y2 预测日PM10浓度  下载: 导出CSV
下载: 导出CSV
表 2 聚类结果
类别 PM2.5 PM10 测试集数 平均浓度/
μg·m−3测试集数 平均浓度/
μg·m−3第一类 229 19.66 155 47.57 第二类 67 46.85 81 60.07 第三类 37 112.78 96 109.53 第四类 33 169.25 34 186.37
下载: 导出CSV
表 3 不同模型预测性能的比较
颗粒物 模型 MAE/μg·m−3 RMSE/μg·m−3 准确率/% PM2.5 LIBSVM 10.65 14.97 77.6 RF-Kmeans-LIBSVM 7.13 11.00 85.0 PM10 LIBSVM 16.96 22.18 78.7 RF-Kmeans-LIBSVM 14.29 19.73 82.0
下载: 导出CSV
-
[1] 闫绪娴, 范玲, 施江南. 我国空气质量综合指数时空分布特征及其对旅游效益的影响——基于31个主要旅游城市情况的分析[J]. 陕西师范大学学报: 哲学社会科学版, 2020, 49(2): 125 − 138. [2] 张丹. 我国城市大气污染现状及防治对策[J]. 中国资源综合利用, 2019, 37(12): 156 − 158. doi: 10.3969/j.issn.1008-9500.2019.12.046 [3] 田瑜, 王金艳, 钟翠萍, 等. 兰州市大气环境因素对过敏性鼻炎和慢性鼻炎的影响[J]. 兰州大学学报(自然科学版), 2016, 52(6): 789 − 795. doi: 10.13885/j.issn.0455-2059.2016.06.011 [4] 刘志强, 王玲, 张爱红, 等. 基于贝叶斯模型的雾霾天高速公路交通事故发生机理研究[J]. 重庆理工大学学报(自然科学), 2018, 32(1): 43 − 49. [5] 吉庸, 顾申枫. 上海地区生活环境中主要空气污染物浓度与儿童哮喘发生率的关系[J]. 海南医学, 2019, 30(4): 471 − 474. doi: 10.3969/j.issn.1003-6350.2019.04.018 [6] 李全喜. 兰州市气象和环境因子对脑出血和冠心病的影响研究[D]. 兰州: 兰州大学, 2019. [7] 先世友. 大气颗粒污染物对户外运动人群心肺功能的不利影响研究[J]. 环境科学与管理, 2020, 45(10): 77 − 81. doi: 10.3969/j.issn.1673-1212.2020.10.017 [8] 李璐, 刘永红, 蔡铭, 等. 基于气象相似准则的城市空气质量预报模型[J]. 环境科学与技术, 2013, 36(5): 156 − 161. doi: 10.3969/j.issn.1003-6504.2013.05.031 [9] 李嵩, 王冀, 张丹闯, 等. 大气PM2.5污染指数预测优化模型仿真分析[J]. 计算机仿真, 2015, 32(12): 400 − 403. doi: 10.3969/j.issn.1006-9348.2015.12.086 [10] 孙宝磊, 孙暠, 张朝能, 等. 基于BP神经网络的大气污染物浓度预测[J]. 环境科学学报, 2017, 37(5): 1864 − 1871. doi: 10.13671/j.hjkxxb.2016.0391 [11] 孙全德, 焦瑞莉, 夏江江, 等. 基于机器学习的数值天气预报风速订正研究[J]. 气象, 2019, 45(3): 426 − 436. doi: 10.7519/j.issn.1000-0526.2019.03.012 [12] 李颖, 陈怀亮. 机器学习技术在现代农业气象中的应用[J]. 应用气象学报, 2020, 31(3): 257 − 266. doi: 10.11898/1001-7313.20200301 [13] ZHANG H, WU P B, YIN A J, et al. Prediction of soil organic carbon in an intensively managed reclamation zone of eastern China: Acomparison of multiple linear regressions and the random forest model[J]. Science of the Total Environment, 2017, 592(8): 704 − 713. [14] 李龙, 马磊, 贺建峰, 等. 基于特征向量的最小二乘支持向量机PM2.5浓度预测模型[J]. 计算机应用, 2014, 34(8): 2212 − 2216. doi: 10.11772/j.issn.1001-9081.2014.08.2212 [15] 刘杰, 杨鹏, 吕文生, 等. 基于气象因素的PM2.5质量浓度预测模型[J]. 山东大学学报(工学版), 2015, 45(6): 76 − 83. doi: 10.6040/j.issn.1672-3961.0.2014.214 [16] 李勇, 白云, 李川. 基于小波分析与BP神经网络的PM10浓度预测模型[J]. 环境监测管理与技术, 2016, 28(5): 24 − 28. doi: 10.3969/j.issn.1006-2009.2016.05.006 [17] 梁泽, 王玥瑶, 岳远紊, 等. 耦合遗传算法与RBF神经网络的PM2.5浓度预测模型[J]. 中国环境科学, 2020, 40(2): 523 − 529. doi: 10.3969/j.issn.1000-6923.2020.02.007 [18] 李芬, 杨程, 赵晋斌, 等. 基于天气类型聚类和LSTM的PM2.5短期预测模型[J]. 水电能源科学, 2021, 39(3): 199 − 202. [19] SURHONE L M, TENNOE M T, HENSSONOW S F, et al. Random forest[J]. Machine Learning, 2010, 45(1): 5 − 32. [20] NAGHIBI S A, AHMADI K, DANESHI A. Application of support vector machine, random forest, and genetic algorithm optimized random forest models in groundwater potential mapping[J]. Water Resources Management, 2017, 31(9): 2761 − 2775. doi: 10.1007/s11269-017-1660-3 [21] BELGIU M, DRAGUT L. Random forest in remote sensing: A review of applications and future directions[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 114(4): 24 − 31. [22] CHEN T, TRINDER J C, NIU R Q. Object-oriented landslide mapping using ZY-3 satellite imagery, random forest and mathematical morphology, for the three-gorges reservoir, China[J]. Remote Sensing, 2017, 9(4): 333. doi: 10.3390/rs9040333 [23] 付旭东. 基于机器学习的短时风场预报与订正研究[D]. 兰州: 兰州大学, 2020. [24] 喻其炳, 李勇, 白云, 等. 基于聚类分析与偏最小二乘法的支持向量机PM2.5预测[J]. 环境科学与技术, 2017, 40(6): 157 − 164. [25] 王慧勤, 雷刚. 基于LIBSVM的风速预测方法研究[J]. 科学技术与工程, 2011, 11(22): 5440 − 5442. doi: 10.3969/j.issn.1671-1815.2011.22.051 [26] 张代林, 王帅, 张小勇. LIBSVM回归算法在焦炭强度预测中的应用[J]. 钢铁, 2018, 53(11): 14 − 21. doi: 10.13228/j.boyuan.issn0449-749x.20180144 -
 点击查看大图
点击查看大图
图( 9) 表( 3)
计量
- 文章访问数: 1212
- HTML全文浏览数: 1212
- PDF下载数: 13
- 施引文献: 0

