


 下载:
下载:


-
随着我国工业化的发展,空气污染等问题日益加剧,其中雾霾造成的危害最为严重。PM2.5浓度是衡量雾霾的一项重要性指标,它是一种直径小于等于2.5 μg的颗粒物,浓度值越大代表空气污染越严重,富含大量的有害物质,能够长期悬浮在空气中,影响空气环境质量和威胁着人们的身体健康[1];其能够导致大气能见度的降低,影响着人们的出行安全,PM2.5浓度的增加还会引起呼吸道疾病,且有研究表明PM2.5与心血管损伤有关,对人体血管内皮细胞产生不良影响。以Web of Science和CNKI 为数据源、PM2.5为关键词,发现国内外的相关文献呈大幅度上升趋势,PM2.5污染问题已逐渐成为研究热点[2]。
近年来,机器学习算法的应用领域越来越广泛,很多学者开始使用机器学习算法来预测空气质量且取得较好的研究成果[3-6];LIU et al[7]用SVR建立空气质量指数(AQI)回归预测模型,研究发现将机器学习与空气质量预测相结合是解决一些环境问题的一种高效、方便的方法;李栋等[8]提出一种基于相关分析、自回归分布滞后模型(ARDL)、果蝇优化算法(FFOA)、核极限学习机(ELM)的PM2.5日浓度回归预测混合模型,并应用在关中地区5个城市,且拟合优度达到0.95;HU et al[9]基于随机森林算法使用气象数据、AOD数据和土地利用因素建立模型,在预测24 h内PM2.5浓度值取得了较好的效果;杨云等[10]采用遗传算法对BP神经网络进行优化建立PM2.5小时浓度预测,结果发现所提出模型优于BP神经网络;LEE et al[11]提出了一种基于梯度提升方法,使用历史污染物及气象数据预测第2日空气质量AQI,结果发现此方法取得显著成果;SONG et al[12]探讨了气象要素与AQI之间的关系,建立了武汉市AQI预报模型,模型能有效预测每日AQI,并发现武汉市AQI夏季低,冬季高;PAK et al[13]提出一种时空卷积神经网络(CNN)和长短期记忆(LSTM)模型建立了北京市第二日PM2.5浓度值预测模型,所提出的方法考虑了空间关系;宋飞扬等[14]把KNN与LSTM算法相结合,所构建的模型考虑了时空特征,相对于LSTM模型误差有所降低;黄婕等[15]采取Stacking集成策略将循环神经网络RNN与卷积神经网络CNN相结合,该模型能够用于大范围区域PM2.5小时浓度预测。
前人使用机器学习算法预测PM2.5浓度取得了较好成果,但大多是小时级或下一日PM2.5浓度预测,能够对空气质量连续多日预测的研究较少。本文以青岛市主城区为研究对象,基于集成学习算法利用分析处理后的历史气象因素和污染物浓度数据,选择随机森林(RF)和梯度提升树(GBDT)算法分别构建PM2.5浓度未来7日监测预报模型,最后使用决定系数R2、RMSE和MAE评估回归模型的性能,探讨在小样本条件下PM2.5浓度有效预测方法,以期为人类出行方式、政府决策等提供理论和方法支撑。
全文HTML
-
研究区域青岛市位于山东半岛南部,别称“琴岛”、“岛城”,位于35°35′~37°09′N、119°30′~121°00′E,东、南濒临黄海,是我国重要的沿海城市,地势东高西低,中间低凹,南北两侧隆起;地处于北温带季风区域属于温带季风气候,由于受到来自海洋面上的东南季风的影响,又具有显著的海洋性气候特征[16];青岛市多海雾发生,水汽充足,为生成污染颗粒物创造了条件,且城市取暖和工业发展都以煤炭为主,也造成了大气中大量颗粒物的产生。
-
本研究使用的数据为青岛市主城区2017年1月1日至2019年12月31日9个空气质量国控监测站点的日均浓度数据,监测站点的站名分别为李沧区子站、城阳区子站、市北区子站、市南区东部子站、市南区西部子站、黄岛区子站、崂山区子站、四方区子站和仰口,数据来自青悦开放环境数据中心(http://data.epmap.org/);数据中包括PM 2.5_24 h(PM2.5颗粒物24 h滑动平均)、SO2_24 h(二氧化硫24 h滑动平均)、CO_24 h(一氧化碳24h滑动平均)、NO2_24 h(二氧化氮24 h滑动平均)、O3_24 h(臭氧日最大1 h平均)、O3_8h_24h(臭氧日最大8 h滑动平均)和PM10 24 h(颗粒物PM10的24 h滑动平均)7个指标。历史气象数据来自中国气象网(http://www.cma.gov.cn/),提取出青岛市与空气质量数据相同时间段的气象条件数据,包括湿度、日照时数、气温、风速、蒸发量、地表气温、降水量和气压8个气象因子,其中如地表气温包括日最高气温、日最低气温和平均气温3个变量因素,8个气象因子共22个变量因素。根据PM2.5检测网新标准,24 h平均值标准划分,见表1。
-
获取的原始数据存在部分缺失及具有特殊意义的数值,污染物浓度数据集中的空缺值选择前后两日无缺失数据的均值进行填充,见图1。
图1可知,SO2_24 h及O3_24 h数据中存在个别异常点,删除样本中包含SO2_24 h>70及O3_24 h中>350的数据;在城市中心区域的每日空气质量基本不可能出现0污染的情况,PM2.5浓度值为“0”可判断为异常监测数据,选择删除PM2.5为0的数据。描述性统计信息可以直观的展现数据的总体分布情况及发现数据中的异常,检查数据是否符合实际情况满足分析的要求,从而对数据进行相应的处理与分析。
对气象因素进行描述性统计,部分气象变量因素的描述性统计特征结果,见表2。
表2可知,数据中存在异常值,分析发现在气象因素中,数值‘32 766.00’表示数据缺测,选择与污染物浓度相同的缺失值填充方式;降水量中包含数值‘32 700.00’及‘999 990.00’表示降水“微量”的情况,选择数值‘0’进行替换;选取历史污染物浓度与气象数据共29个变量作为模型的输入变量x,预测日期污染物PM2.5浓度数据作为模型输出变量y。处理后的数据样本量共5 836条,为验证模型的精度,将数据集划分为2个部分,选取前7个监测站点4 532条数据训练模型,四方区子站、仰口2个监测站点共1 304条数据作为模型的验证集。
-
对单个基学习器来讲,通常具有一定局限性,模型的学习能力相对较弱;集成学习是一种整合多个基学习器的学习结果,从而得到一个预测效果更好的机器学习算法,能够提高模型分类或回归的准确率[17],模型表现的也更稳定,见图2;常见的2种集成学习算法:基于Boosting和基于Bagging的算法[18]。基于Boosting的算法主要为梯度提升决策树(GBDT,Gradient boosting decision tree)等,基于Bagging的算法有随机森林(RF,Random forest)。
-
随机森林算法(RF)最早由BREIMAN[19]提出,是一个包含了多个决策树的学习器,能够处理高维数据且不用进行特征选择,具有学习速度快、不易过拟合、泛化能力强等特点;随机森林回归(RFR)是基于多个回归树模型
$\{ T(x,{\theta _m}),m = 1,2,......d\}$ 构成的组合回归模型[19],模型的预测结果为多个树模型的均值,相对于其他算法有较高的优势,对数据特征的学习能力较强,算法的主要步骤为:(1)原始数据集记为
$D = \left\{ {{x_{i1}},{x_{i2}}, \ldots \ldots ,{x_{in}},{y_i}} \right\}$ $(i \in [1,n]) $ ,采用有放回抽样Bagging方法从数据集D中随机抽样,得到$d$ 个子样本集${D_i}(i = 1,2,......d)$ ;(2)构建基学习器(决策回归树):对每一个抽样
${D_i} = \left\{ {{x_{i1}},{x_{i2}},......{x_{id}},{y_i}} \right\}\left( {i \in [1,n]} \right)$ 样本集分别建立回归模型$\left\{ {T(x,{\theta _m}),m = 1,2,......d} \right\}$ ,其中自变量矩阵x用来建模,设参数集$\left\{ {{\theta _m}} \right\}$ 独立同分布,记录每一棵树的结果$T\left( {x,\theta } \right)$ ;(3)训练
$d$ 次后得到决策回归树模型$\{ T\left( {x,{\theta _1}} \right),$ $T\left( {x,{\theta _2}} \right),......,T\left( {x,{\theta _d}} \right)\} $ ,对于新给定的样本,RFR模型预测结果,见式(1)。 -
梯度提升决策树(GBDT)算法以决策树为基函数,它的泛化能力强、预测能力快,能很好解决过拟合问题,为解决一般损失函数优化问题,提升方法采用加法模型及前向分布算法[20-21],见式(2)。
式(2)中,
$T\left( {x;{\theta _m}} \right)$ 为决策树;${\theta _m}$ 决策树参数;M为树的个数。提升树使用前向分算法,首先使
${f_0}\left( x \right) = 0$ ;第m步的模型,见式(3)。需最小化求解参数θ,第m颗树的参数θ,见式(4)。
当采用平方误差损失函数时,见式(5)。
式(5)中,
$r = y - {f_{m - 1}}\left( x \right)$ 为当前模型残差,每次模型采用的数据都是此残差,这个残差会逐渐减小。算法的流程如下:
(1)初始化
${f_0}(x) = 0$ ;(2)对于
$m = 1,2,3, \cdots ,M$ :①计算残差
${r_{mi}} = {y_i} - {f_{m - 1}}\left( {{x_i}} \right), \cdots i = 1,2, \cdots ,N$ ;②拟合残差
${r_{mi}}$ 学习一颗回归树$T\left( {x;{\theta _m}} \right)$ ;③更新
${f_m} = {f_{m - 1}}\left( {{x_i}} \right) + T\left( {x;{\theta _m}} \right)$ ;(3)得到回归提升树
${f_M}(x) = \sum\limits_{m = 1}^M {T\left( {x;{\theta _m}} \right)} $ 。
1.1. 研究区概况
1.2. 数据获取
1.3. 数据预处理
1.4. 研究方法
1.4.1. 随机森林












1.4.2. 梯度提升决策树











-
空气污染物和部分气象因素与第二日PM2.5浓度的Pearson相关系数,见表3。
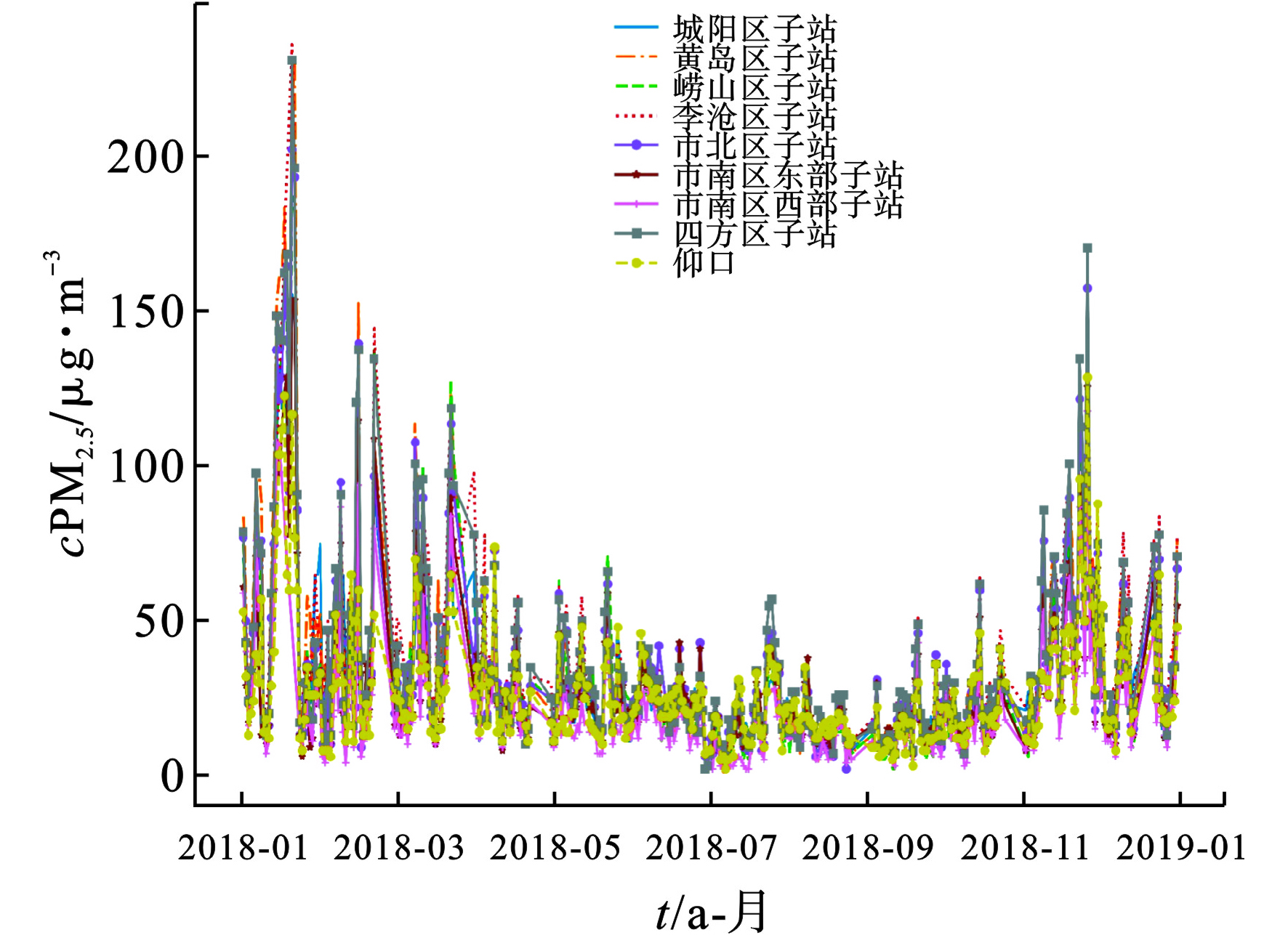
其中,第二日PM2.5值与前一日PM2.5值相关性较大为0.70,这是由于大气的污染具有延迟性,相邻两日的PM2.5浓度相似;与其具有正相关性的其他空气污染物按照强弱顺序依次是CO、PM10、NO2和SO2,O3与PM2.5成负相关性,即当CO、PM10、NO2和SO2升高时,PM2.5浓度也会随之升高,O3的升高会伴随着PM2.5的下降。气象因素与大气颗粒物存在着密切联系[22-24],相关系数表明气象因素中除气压外,其他因素与PM2.5均为负相关,例如降雨会冲刷空中漂浮的风尘,因此可以改善空气质量;风向能够影响PM2.5颗粒物的扩散、聚集,青岛市冬季风向多为北风、西北风,将其他地区如京津冀地区和山东省西部城市的空气中的污染颗粒物带到青岛市,导致了冬季青岛市PM2.5浓度的增高,夏季风向多为南风、东南风,海风带来清洁空气使青岛市内部的污染物浓度降低。青岛市主城区9个空气质量监测站点PM2.5日均浓度年变化趋势,见图3。
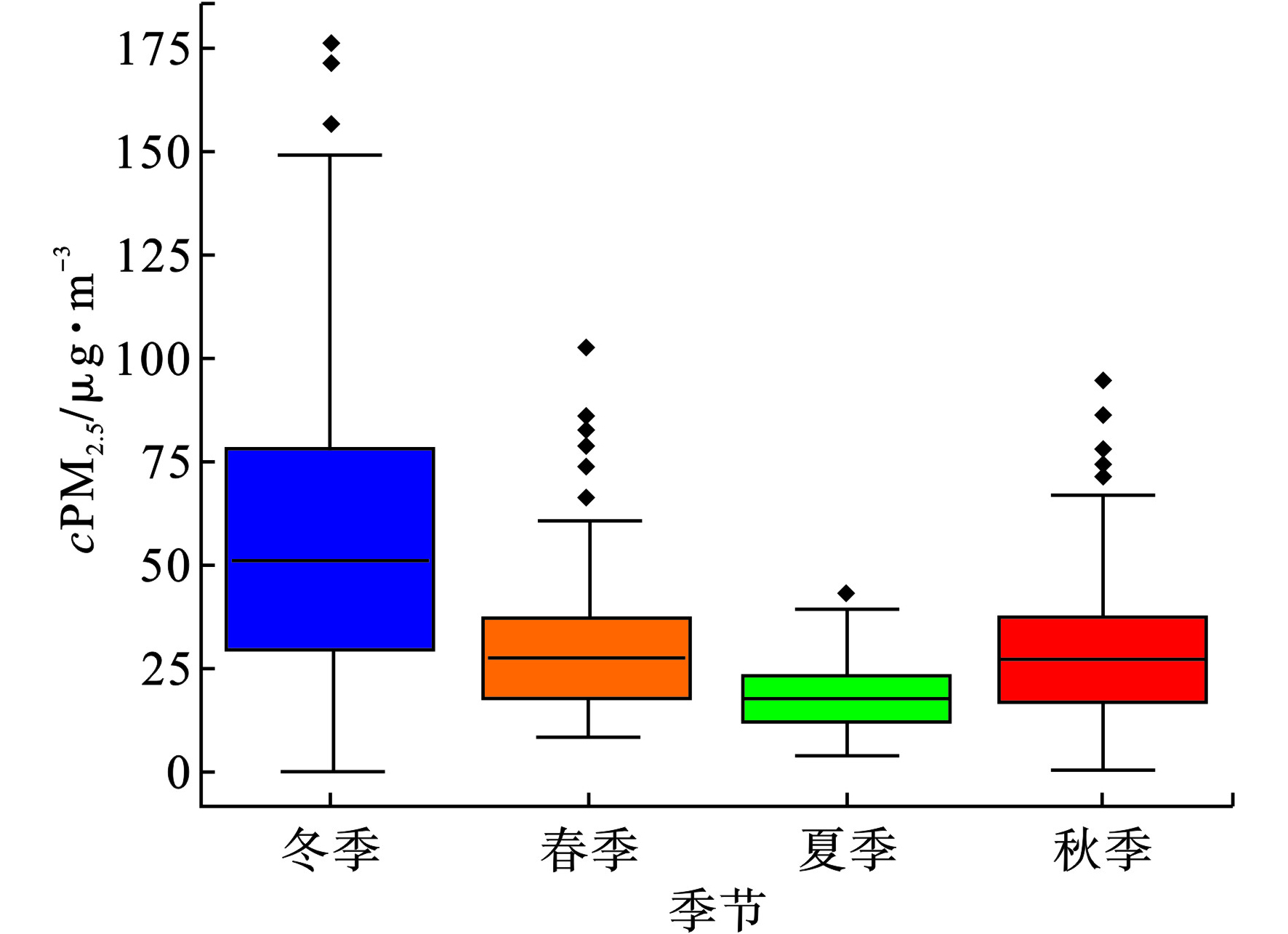
图3可知,空气质量监测站在时间上有相同的变化趋势;PM2.5浓度值在12月、1月和2月份浓度值较其他月份有很大的增高趋势,尤其1月份为全年PM2.5浓度最高月份,部分日期中PM2.5浓度值>150 μg/m3,空气质量等级为中度污染,出现此状况的主要原因之一与冬季城区由于供暖进而增加了污染物排放量有关。PM2.5浓度在6、7和8月份浓度值最低,位于0~50 μg/m3之间,空气质量等级为优,适合户外活动呼吸新鲜空气。春秋季节PM2.5浓度值在50 μg/m3上下波动,空气质量等级基本为优和良,研究站点在研究日期中未出现浓度值>50 μg/m3严重污染的情况。将日期转化为四季类别数据,对于分类后的季节类型数据,箱线图直观表明了PM2.5浓度值在4个类别上的总体分布情况,见图4。
图4可知,冬季PM2.5浓度相对较高,夏季PM2.5浓度最低;由此可以看出青岛市PM2.5浓度值的变化受到季节的影响,因此把季节因素作为特征变量添加到输入变量x中以提高模型精度,
-
为了充分验证模型的精度,样本数据分为训练集和验证集,7个空气质量监测站点的数据作为训练集,2个空气质量监测站的数据用来验证模型的精度,分别构建未来7日的PM2.5浓度预测模型,具体步骤为:(1)将训练集中特征矩阵x和第二日PM2.5浓度值y分别作为模型输入和输出训练模型,用训练好的模型预测第二日的PM2.5浓度;(2)把预测的第二日PM2.5浓度添加到特征矩阵x中,构建预测第3日的PM2.5浓度,依次分别建立未来7日的PM2.5浓度预测模型。为验证集成学习算法的优越性,选取线性回归(LR,Linear regression)和决策树(DT,Decision tree)与梯度提升树(GBDT)、随机森林(RF)算法对验证集的预测结果进行对比。选取决定系数(R2)、MAE(平均绝对误差)和均方根误差(RMSE)对模型精度进行评价,各模型在验证集上对第二日PM2.5预测值的评价结果,见表4。
表4可知,LR模型在验证站点上的拟合精度R2分别为0.83和0.82,RMSE和MAE相对较大;DT算法的拟合精度R2分别为0.83和0.61,RMSE和MAE均小于LR模型结果;基于集成学习算法的RF及GBDT算法要明显优于DT和LR模型,RF拟合精度R2分别为0.93和0.83,GBDT拟合精度分别为0.94和0.83,两种算法的MAE及RMSE大大降低。
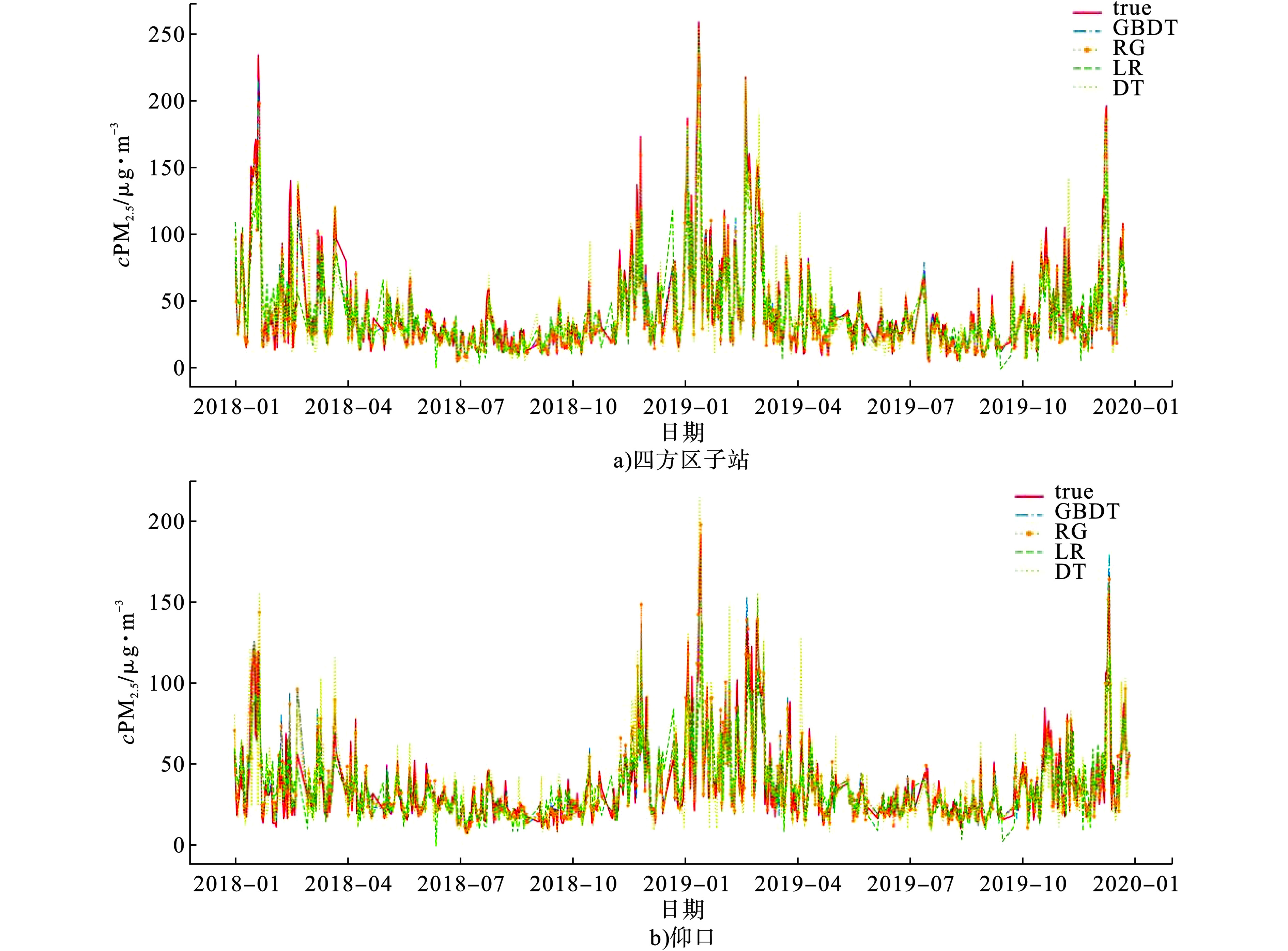
2个验证站点在4种模型上的预测结果与真实值的对比,见图5。
图5可知,LR模型预测误差最大,在极值处预测效果较差,DT模型在浓度值较高时预测精度最低,GBDT和RF算法具有更高的准确性符合站点PM2.5浓度的真实趋势,在极值点的预测效果也较好,选择GBDT和RF算法分别建立未来7日浓度预测模型。
RF和GBDT模型对未来7日PM2.5浓度预测结果,见表5。
表5可知,集成学习算法RF和GBDT具有相似的预测精度,均能够有效预测青岛市监测站点所在位置7日内的PM2.5浓度值,预测结果拟合精度高、误差小、训练结果稳定。随着预测日期跨度的增加预测精度有所下降,上一日的预测误差会影响到下一日的预测上,四方区子站对未来7日预测结果精度较高,拟合精度均>0.90,在仰口站点上的预测精度相对小于四方区子站精度,但第7日的预测结果R2也>0.70;今后将继续探讨所建立模型在不同地域中的实现应用,为大气污染动态监测提供理论和方法支持。
2.1. 影响因素相关性分析
2.2. 模型建立与精度分析
-
针对空气中PM2.5浓度值预测问题,本研究考虑了气象因素和其他空气污染物与PM2.5浓度的关系,对历史数据集进行分析及处理,以青岛市区为研究对象,建立了基于集成学习算法的PM2.5浓度预测模型,并选择单一模型作为对比模型,得出以下结论。
(1)模型输入变量的选择影响着模型的预测结果,数据的预处理能够提高模型预测的准确率,其中CO、PM10、NO2和SO2与PM2.5成正相关,O3与PM2.5成负相关;气象因素与PM2.5也存在着紧密联系,除气压外其他因素日照时数、气温、风速、蒸发量、地表气温、湿度和降水量与PM2.5浓度均成负相关;季节的变化影响着PM2.5浓度的变化,冬季的PM2.5浓度较高,夏季较低。
(2)相比单一回归模型,集成学习算法合并了多个基模型的预测结果,训练结果更稳定,泛化能力较强,能够较好地捕捉各输入变量与PM2.5浓度间的非线性关系。对比第二日各模型预测精度,线性回归LR具有最大误差,决策树DT预测结果不够稳定,随机森林RF和梯度提升树GBDT的拟合优度高,误差小,预测结果较准确。
(3)RF和GBDT对未来7日的PM2.5浓度均值预测均取得较好的成果,能够较准确的预测未来PM2.5日均浓度变化趋势;预测误差存在累积性,预测精度会随着时间跨度的增大而降低,上一日的预测误差会影响到下一日的预测结果。
